The last 6 months of my life have been living hell thanks to Cisco. I was assigned a relatively simple project of configuring some CSR1000v virtual routers in Amazon Web Services for the purpose of DMVPN spoke termination. It has been miserable thanks to the unprecedented number of bugs on a product that’s over 5 years old.
Adding to the confusion, the primary issue is specific to the t2.medium instance type. Since these are by far the cheapest instances and support up to 250 Mbps throughput (more than adequate for most organizations) I suspect I’m not the first to encounter problems, but am the first to find the root cause.
Problem #1 – They crash!
We launched the first batch of CSR1000vs in January 2019. I had meant to tell the person launching them to try and do very 16.6 since that was the company standard for IOS-XE, but they defaulted to 16.9.1. However, everything seemed fine as basic configuration and connectivity tests were successful. But a few days after launching some test instances, I noticed the routers had rebooted unexpectedly. Fortunately this was easy to diagnose since there were crash files I could provide TAC. The bug was this:
CSCvk42631 – CSR1000v constantly crashes when processing packets larger than 9K
Since most instances launched in AWS have a 9001 Byte MTU by default, going with this version was a non-starter. No problem, 16.9.2 was already available so that’s an easy fix….or so I thought.
Problem #2 – They stop passing traffic
I copied over 16.9.2 and 16.6.5 software images. Initially I just booted 16.9.2 to verify they no longer crashed. Welp, now we have a different problem.
The systems team said they had lost connectivity in the middle of the day. I tried logging in to the CSR1000v via its external internal and could not access it. However, I was able to access the peer router and then hop in via the private interface. I saw that the external interface had “no ip address assigned”, which would indicated it lost connectivity to the DHCP server and failed renewal.
Around this time I started scanning Reddit. A user mentioned trying to roll out CSR1000vs on t2.mediums with DMVPN configured and having similar stability woes. Cisco was of little use, but Amazon support blamed it on CPU micro-bursts likely caused by route changes. Switching the instances from t2.medium to c4.large resolved the issue. This really didn’t make sense to me, but I could see cases where bursts were triggering a near exhaustion of CPU credits. I looked at CloudWatch and indeed would see cases of the CPU credit balances suddenly dropping, but could not tell if this was the root cause or simply a secondary symptom of it not passing traffic. After doing some reading on this topic I switched the instances to T2 unlimited, but even after a reboot, there was no behavioral change.
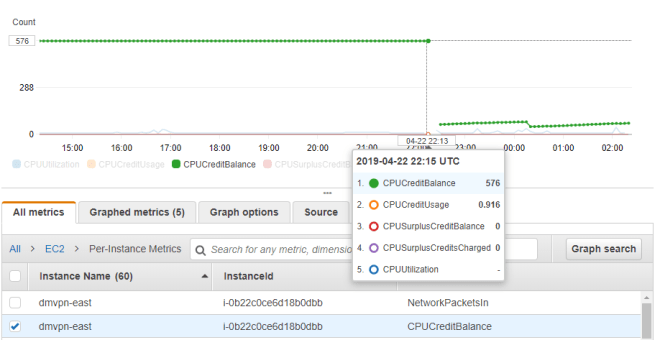
I also followed the CPU red herring trail for a bit longer and found this
Features—Cisco IOS XE Fuji 16.7.1 The following new software features are supported on the Cisco CSR 1000v for Cisco IOS XE Fuji 16.7.1. - Templates for vCPU allocation and distribution—including the Control Plane heavy template.
Sure enough, you can see lower on average CPU usage when upgrading to 16.7 and newer trains
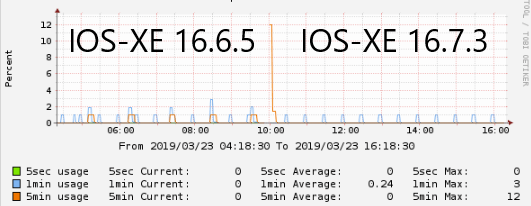
But this is still overall very low CPU usage that should certainly not be causing an interface to stop passing traffic entirely. So we’re back to square one.
I’m now caught between a rock and a hard place because 16.6.4 and 16.9.1 will cause the router to crash and reboot, but 16.6.5 and 16.9.2 will cause one of the interfaces to stop passing traffic. The work-around I came up with was create IP SLA monitors to ping the adjacent gateways combined with an EEM script to auto-reboot upon detection.
Update April 26th 2019: We have a bug ID! CSCvp48213
Update May 24th 2019: We have a root cause. It’s a problem related to Generic Receive Offload (GRO) being enabled at the Linux kernel level. This will be fixed in 16.9.4 or 16.6.6, which are due out towards the end of 2019 😐
Update June 6th 2019: I went back at the original bug and have a theory what the problem is. Looks like between 16.9.1 and 16.9.2 they lowered the MTU at the vNIC level to 1500 bytes:
Router#show platform software system all VNIC Details ============ Name Mac Address Status Platform MTU GigabitEthernet1 12bf.4f69.eb56 UP 1500 GigabitEthernet2 1201.c32b.1d16 UP 1500
To me, this seems much more like a hackish workaround that a fix.
Problem #3 – Internal traffic is fine, but Internet traffic is painfully slow
After working through the above two problems, I finally got time to try upgrading to 16.10.1b. Surprisingly, this fixed the stability problem. No more crashes, no more freeze-ups. But upon doing more detailed testing, we found a new issue – when using the CSR1000v for internet access (via NAT), speeds were horribly slow. I would get 125 KBps at best despite having verified the 100 Mbps license was installed and “platform hardware throughput level” was configured and enabled.
ubuntu@ip-10-13-22-161:~$ curl ftp://ftp.freebsd.org/pub/FreeBSD/releases/i386/i386/ISO-IMAGES/11.2/FreeBSD-11.2-RELEASE-i386-bootonly.iso > /dev/null % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 261M 100 261M 0 0 30733 0 2:28:55 2:28:55 --:--:-- 92708
Very much seemed like a licensing issue since 125 KBps = 1 Mbps which is the speed set in evaluation mode. But speeds going over an IPSec VPN tunnel were up to 50 Mbps, which made no sense.
Opened another TAC case and got nowhere. Once again I’m on my own, so I desperately started reading release notes and find this:
CSCvn52259 – CSR1Kv:Throughput/BW level not set correctly when upgrade to 16.10.1 .bin image with AWS/Azure PAYG
I would suspect this has something to do with Smart licensing, since it is mandatory starting with version 16.10