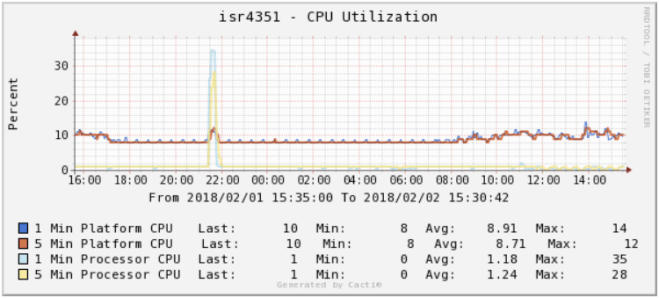
One important thing to understanding in IOS-XE is the different numbers that can be returned when checking CPU and memory statistics. There’s some very down in the weeds docs on this, but the simplest way to break it down is process vs. platform. Processes is essentially control plane, while platform is data plane.
CPU
Processor CPU
CLI command: show processes cpu
SNMP OIDs:
1.3.6.1.4.1.9.2.1.56.0 = 5 second 1.3.6.1.4.1.9.2.1.57.0 = 1 minute 1.3.6.1.4.1.9.2.1.58.0 = 5 minute
Platform CPU
CLI command: show processes cpu platform
SNMP OIDs:
1.3.6.1.4.1.9.9.109.1.1.1.1.3.7 = 5 second 1.3.6.1.4.1.9.9.109.1.1.1.1.4.7 = 1 minute 1.3.6.1.4.1.9.9.109.1.1.1.1.5.7 = 5 minute
Note – Most platforms will be multi-core.
Memory
Processor Memory
CLI command: show processes memory
SNMP OIDs:
1.3.6.1.4.1.9.9.48.1.1.1.5.1 = Memory Used 1.3.6.1.4.1.9.9.48.1.1.1.6.1 = Memory Free
Platform Memory
CLI command: show platform resources
SNMP OIDs:
1.3.6.1.4.1.9.9.109.1.1.1.1.12.7 = Memory Used 1.3.6.1.4.1.9.9.109.1.1.1.1.13.7 = Memory Free 1.3.6.1.4.1.9.9.109.1.1.1.1.27.7 = Memory Committed
Cacti Templates
These were written for Cacti 0.8.8f
https://spaces.hightail.com/space/FoUD1PvlXA
 BIND servers will typically ship with a factory-default hint zone like this:
BIND servers will typically ship with a factory-default hint zone like this:


